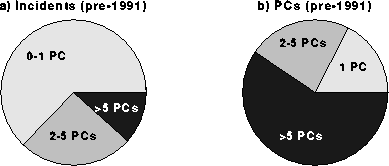Jeffrey O. Kephart and Steve R. White
High Integrity Computing Laboratory
IBM Thomas J. Watson Research Center
P.O. Box 704, Yorktown Heights, NY 10598
We are interested in understanding the extent of the computer virus problem in the world today, with an eye towards being able to predict what it will be like in the future. We discuss in detail the sorts of questions that must be answered in order to form an accurate picture of the situation. One approach to collecting such data, taken by Dataquest and Certus, is to survey security experts responsible for many PCs within their organization. We recommend a number of improvements that can be made to such surveys, and present a different methodology for measuring various aspects of the computer virus problem which possesses some important advantages. We have studied a large, stable population of PC DOS users for the past several years, recording information about virus incidents as they occurred. While the number of viruses that have been written has increased dramatically, only a small fraction have been seen in real incidents. Of this fraction, just a few viruses account for most of the incidents. While the number of incidents caused by all viruses each quarter is increasing, its increase is not nearly as dramatic as some have predicted. Some viruses are responsible for more incidents than in the past, while others are stable or declining in number. We conclude that, although there are ongoing infections by a number of viruses in the world as a whole, the susceptibility of our particular sample population to infection has decreased measurably as a result of user education, widespread dissemination of anti-virus software, and centralized reporting. Although we have learned much from our study, considerably more work is required before we can reliably forecast the most important aspects of the computer virus problem.
In order to formulate well-grounded anti-virus policies and measures, it is essential for us to understand at least two things. First, how likely is a given user or group of users to experience a computer virus today or at some point in the future? Second, what are the likely costs and other consequences of infection? In this paper, we focus on the first of these questions, separating it clearly into several components. Then, we discuss how one can measure these various aspects of the computer virus problem, both in the world as a whole and in a particular environment. We provide answers to some of these questions by presenting results that we have obtained by monitoring a large population of computer users over a period of several years. Finally, we compare our results with those of the 1991 Dataquest survey, using the opportunity to illustrate some pitfalls of data collection and interpretation that one should strive to avoid.
There are several important aspects of the computer virus problem that need to be understood. Hundreds of different PC viruses have been written, and their number is increasing rapidly. However, only a small minority are actively spreading; the majority are rarely seen outside of virus collections. It is important to know which ones are most prevalent, so as to focus our anti-virus effort properly. We would also like to monitor the prevalence of the most common viruses as a function of time and geographic location. This would allow us to fit their growth or decline to theoretical or phenomenological models, which could be used to project their future course. As an additional benefit, we might use such information to estimate how much time we typically have to derive detectors and cures for new viruses, which affects the required frequency of updates to virus scanners and other anti-virus software.
The above considerations are reasonably adequate if we are satisfied with a global perspective on the computer virus problem. However, in order to assess a particular organization's risk of infection, we must gain some insight into what causes some environments to be more conducive to viral spread than others. For example, a good deal of anecdotal evidence suggests that educational institutions are more vulnerable than others. In order to quantify this and other such correlations between organizational type and viral prevalence, we must measure the prevalence of computer viruses in large and small businesses, homes, educational institutions, and government agencies.
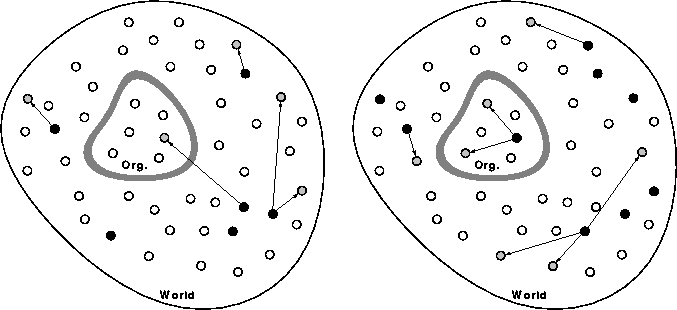
From an organization's perspective (illustrated in Fig. 1), the world is full of computer viruses that are continually knocking on the door, trying to get in.
Figure 1: Computer virus spread from an organization's perspective.
White circles represent uninfected machines, black circles represent infected
machines, and gray circles represent machines in the process of being infected.
Throughout the world, computer viruses spread among PCs, many of them being
detected and eradicated eventually. Left: Occasionally, a virus penetrates
the boundary separating the organization from the rest of the world, initiating
a virus incident. The frequency with which this occurs depends upon the
fraction of infected machines in the world, the number of machines in the
organization, and the success of the organization in filtering out infectious
contacts with the outside world. Right: The infection has spread to other
PCs within the organization. The number of PCs that will be infected by
the time the incident is discovered and cleaned up (the size of
the incident) depends upon inherent characteristics of the virus and the
effectiveness of the organization's anti-virus policies, particularly the
extent to which anti-virus software is being used.
An organization should have two complementary goals regarding computer viruses: to reduce their influx from external sources, and to reduce their internal spread if they do get in. Each time a virus penetrates an organization's defenses from some external source, it instigates what we shall term an incident -- a cascade of infections that reaches some number of PCs (the size of the incident) and diskettes before being discovered and eradicated. In our definition, the incident size would be zero if a virus on a foreign diskette were detected by the organization before the virus had a chance to infect any machines. Note also that a recurrence of an incident (e.g. due to imperfect cleanup) is to be counted as part of the original incident, not a new one.
It is essential to distinguish between the number of incidents and the number of infected PCs and diskettes that an organization has experienced. These statistics reflect two different aspects of an organization's ability to manage the problem of computer viruses, and must not be confused with one another; unfortunately, they often are. By our definition, the number of incidents is equal to the number of times a virus has penetrated an organization, which in turn depends upon the frequency of that virus in the external world and the effectiveness of the organization in limiting its initial penetration. Some policies that have been advocated for slowing the influx of viruses include forbidding the use of bulletin boards, shareware, and diskettes from home and insisting that all software be centrally acquired and approved. Integrity shells and resident processes which scan memory for known viruses before executing any program are two popular software techniques for hindering the initial penetration of a virus . We suspect that some of these strategies provide a more reasonable balance between convenience and safety than others. However, in order to make well-founded recommendations, we must be able to correlate their use with the observed number of incidents in particular organizations. Of course, even if such policies help, they can not completely stem the flow of viruses. It is necessary to employ another class of anti-virus measures designed to limit the spread of a virus once it has penetrated an organization. The average size of an incident is governed by the virulence of the virus and the effectiveness of the anti-virus measures in place within the organization. In particular, the extent to which anti-virus software is installed and used should be measured, as should the degree to which it is responsible for the initial discovery of a virus. We would like to know what avenues exist for informing other employees or central CERTs (Computer Emergency Response Teams) about virus incidents. Finally, we would like to measure the degree to which the organization's PCs use LAN servers, which can enhance the natural virulence of a virus.
In practice, the original source of infection can not always be determined. For example, an incomplete cleanup from a virus incident may miss an infected diskette, which instigates a second round of infectious spread some time later. It may be difficult to tell that this second ``incident'' is actually a recurrence of the first incident, rather than the result of another penetration from an external source.
At an even finer level of detail, it would be very useful to understand several aspects of user behavior, such as the pattern and frequency of software and diskette exchange between users, the pattern and frequency of software use, and the extent to which anti-virus software is installed and used. Knowledge of these and perhaps other facts about user behavior combined with the other measurements that we have proposed should prove to be of great utility in supporting and calibrating theoretical models. This would provide us with a better understanding of what governs the rate of spread of various types of viruses, which should in turn guide our anti-virus strategy -- allowing us to find a reasonable balance between cost and safety.
We must be content with sampling only a small subset of the world's PCs and diskettes. This in turn requires that we report results using categories that are sufficiently coarse-grained to yield acceptable statistics. Unless our resources are fairly substantial, we might wish to limit our attention to a particular type of user environment or geographic region so as not to thin out our statistics too much. Likewise, resource limitations are likely to prevent us from obtaining more than a hazy picture of user behavior. The least expensive option is probably through surveys, which rely on the questionable ability of people to assess their own behavior accurately. Another option is to study user behavior using a combination of observation by sociologists and monitoring by special-purpose software, both of which are expensive even when the studied population is fairly small.
Some of the information that we wish to collect is for the purpose of determining the current prevalence of computer viruses, and some is useful for providing insight into what factors primarily influence virus prevalence -- allowing us to build and calibrate models which can predict the future situation and guide our anti-virus strategy. To summarize, some of the major categories of questions that we are particularly interested in answering include:
To what extent do they report discoveries of a virus to other users or central agencies?
How do we go about answering the three major categories of questions posed in the last section (which we shall refer to as Q1 through Q3)? As was stated, we are limited to sampling some chosen subset of computer users, typically within a particular type of environment to which we have access.
One approach, which was taken by Certus in 1990 and 1991 and by Dataquest in 1991, is to survey a large number of organizations by contacting the person within each who is most responsible for troubleshooting virus problems. Based upon their surveys, Certus and Dataquest drew conclusions about some aspects of the trends of particular viruses over time and several details of virus incidents (Q1.B and Q2, respectively). Although these surveys do shed some light on the virus problem, many of the results are suspect because they rely on the accuracy of people's recollection. In some cases, respondents were asked to recall events which happened up to two years in the past, and it is not clear how many of them kept accurate records of virus incidents. Underreporting of old virus incidents would not be surprising under such circumstances.
We feel that a much more reliable way to answer these questions is to collect statistics on virus incidents directly from a large chosen population as they occur. For each incident, we must record (at a minimum) where and when the incident occurred, what virus was involved, and how many machines were affected. Other details of virus incidents (e.g. other sub-categories of Q2) would be useful to record as well. This method requires a population with three important characteristics:
We are still left with the other questions which were posed in the previous section. The question of how many different viruses exist in the world (Q1.A) has been debated hotly by several computer virus collectors and pundits. Continuance of the debate is nurtured by several factors:
We are content to let people enjoy their debate. Eventually, some good may come of it. However, we feel that it is much more important to know which few of the untold hordes of viruses are worth worrying about (Q1.B). The set of questions regarding user behavior (Q3) is important, but can not be answered by monitoring virus incidents. A user survey could be useful, although its reliance on people's ability to quantify their own behavior accurately could introduce a substantial amount of error [1]. Software tools which monitor user behavior in certain limited environments might be very useful supplements to such a survey.
Some additional remarks apply to all of the questions posed in the previous section. Whether the information is obtained via surveys or by closely monitoring a large population of users, care must be taken in gathering and interpreting the data. We must define the quantities we are trying to measure carefully and make sure that the data we gather actually measure those quantities and that they are accurate. Even if the data are accurate, there are many pitfalls that must be avoided in their interpretation. For example, both the Certus and Dataquest studies have blurred the distinction between the number of incidents and the number of infected machines, and have in some cases failed to distinguish between the number of infections by one particular virus and the number of infections due to all known viruses. As we will see, attempting to extrapolate from noisy or incomplete data is another such pitfall.
In this section we provide answers to Q1 and Q2, based upon the growth of our virus collection and our study of virus incidents in a large selected population of computer users over a period of several years. The sample population is international, but biased towards the U.S. It is stable, both in makeup and in size. We believe it to be typical of Fortune 500 companies possessing the three important characteristics cited in the previous section -- regular use of anti-virus software, user education, and central reporting of incidents -- plus active central response to incidents. These characteristics give us confidence that the data we collect from the sample population are accurate. Of course, these same characteristics are not typical of many other environments, so some of our results may not be representative of universities, home users, and other businesses which lack the cited characteristics.
Ironically, it is precisely these special properties of our sample population which enable us to draw some important general conclusions about the computer virus problem in the world as a whole. To begin the story of how this is possible, we present in Fig. 2a the distribution of incident sizes during a six-month period when the above-mentioned anti-virus strategies were first being deployed in the various components of our sample population.
Figure 2: a) Fraction of incidents of given size during six-month periods when strategies were first being deployed. b) Fraction of infected PCs involved in incidents of given size during the same time period.
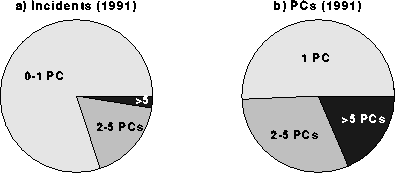
During this period, the average incident size was 3.4 PCs. Most (63%) of the incidents involved just zero or one PCs. (Recall from section 2 that an incident size is defined as zero if a foreign diskette is caught before it can infect any of an organization's PCs.) Only 12% of the incidents involved more than 5 PCs. However, Fig. 2b presents a different view of the same data. Even though incidents larger than 5 PCs were fairly rare, they accounted for 59% of the total number of infected PCs. Thus the larger incidents actually accounted for most of the problem! Fig. 3 shows the corresponding distributions for 1991, after the anti-virus strategies had been in place for some time. The average incident size was cut by more than a factor of two to just 1.6 PCs. In the vast majority of cases (80%), the infection was caught before it could infect more than one PC. Only 2.5% of the incidents involved more than 5 PCs, and these large incidents accounted for only 19% of the total number of infected PCs. We believe that the anti-virus policies that were implemented helped to create a more hostile environment for computer viruses and thus are largely responsible for this marked improvement. We can expect the average incident size to be larger than that of Fig. 3 (and more like that of Fig. 2) in organizations which have not yet implemented active response policies.
Figure 3: a) Fraction of incidents of given size during 1991. b) Fraction of infected PCs involved in incidents of given size during 1991.
Now let us see how we can exploit the small incident size within our population to learn something about the virus problem in the world as a whole. As was noted in the previous section, each incident (according to our definition) stems from infected software that originated outside of the sample population. Of course, in practice it is not always possible to tell whether two ``different incidents'' are really related, and hence should be counted as a single, larger incident. However, since very large virus incidents are and always have been relatively rare in our sample population, we conclude that it is below the epidemic threshold for computer viruses [2]. In other words, our sample population is unable to sustain an ongoing computer virus infection. The lack of much internal spread of viruses makes it easier to believe that the incidents that we record are not merely repercussions of previous internal incidents. The belief that most of our ``incidents'' really arise from an external source is corroborated by another observation: incidents involving uncommon viruses are rarely clustered in time or space, as they would be if the virus were to spread between different parts of the organization or recur at the same location due to an incomplete cleanup. Assume that the success with which viruses enter an organization remains constant in time, and that the organizations in our sample population were exposed to a fairly representative sample of the world's actively-spreading viruses. To the extent to which this is true, the remaining statistics that we present in this section reflect not just characteristics of virus incidents in our sample but also the relative populations of various viruses in the world as a function of time. It is somewhat remarkable that, by studying a single sample population, we are able to distinguish its characteristics from those of the world at large. It is our clear distinction between the number of incidents and the number of infected PCs that enables us to accomplish this feat.
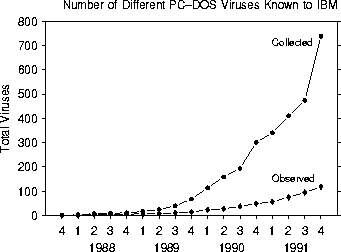
Figure 4 presents one aspect of global virus trends (Q1) -- the number of different viruses in our High Integrity Computing Laboratory collection and the number of different viruses observed in incidents in our sample population as a function of time. We have been able to maintain a current collection of known viruses by working cooperatively with other virus collectors.
Figure 4: Number of viruses known to us (those we have collected and analyzed) and number of viruses ``in the wild'' (observed by us in actual incidents) as a function of time.
As was noted earlier, the number of different viruses is a somewhat fuzzy and debatable notion. We do not adhere rigidly to one specific criterion for determining whether two viruses in our collection are the same, but generally we count two viruses as different only if there are at least several bytes of code that do not match. In the case of degarbling viruses, which use one or more heads to encrypt and decrypt themselves in an attempt to confuse virus scanners, we count all possible realizations of a virus as a single virus. Since our collection can never be completely up-to-date, the number of different viruses in our collection can be taken as an approximate lower bound on the number of viruses in existence in the world. The number of different viruses that have been written has grown dramatically during the last four years, and the rate at which they are being written is accelerating. During the last two years, the number of viruses that we have seen in real incidents has consistently been in the range of 15% to 20% of the total number in our collection, and a majority of these have only been seen once or twice. Thus only a very small minority of computer viruses are very successful.
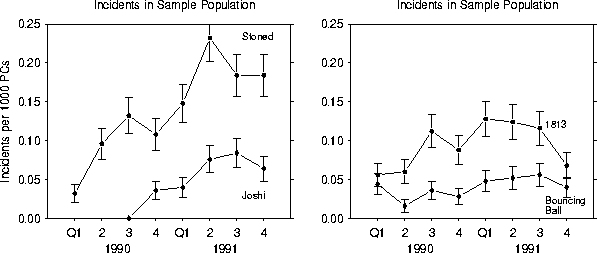
Figure 5 emphasizes the point that a few viruses account for many, but certainly not all, of the observed incidents. During 1991, the Stoned and 1813 (Jerusalem) viruses together accounted for 34% of the observed incidents. The ten most common viruses accounted for 69% of the incidents, with the remaining 31% being distributed among 73 different viruses, half of which were only seen once. A number of other viruses that we have seen in previous years were not observed at all during 1991. This leaves over 600 viruses in our collection that we have never observed at any time. It is interesting to note that the ``market share'' of the Stoned and 1813 viruses has declined from the previous year, when together they accounted for 51% of all incidents. This has occurred despite an increase in the prevalence of both, and can be traced to several new viruses having entered the field in 1991. Some of these newcomers -- notably Joshi, Form, and Tequila -- are proving to be rather successful. Other new viruses are seen only rarely, but there are so many of them that the fraction of incidents in the ``Other'' category is growing rapidly.
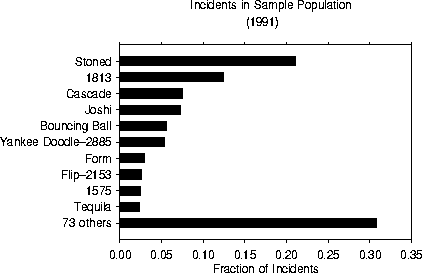
Figure 5: Relative frequency of incidents involving the most common
viruses during 1991.
Figure 6 shows the relative frequency of the four most common viruses as a function of time. There has been a reasonably consistent upward trend in the number of Stoned and Joshi incidents. The prevalence of the Bouncing Ball virus has been fairly stable over the last two years. The rising or stable trends of these and many other viruses indicate that they are above the epidemic threshold in the world at large (but not in our sample population). The 1813 (Jerusalem) increased in prevalence until early 1991, but appears to be leveling off or even declining now. Other viruses which are not shown in this figure are almost certainly in decline, indicating that they are below the epidemic threshold. The Brain is a prime example of a virus which is nearly extinct. Thus some viruses appear to be increasing in prevalence, some are stable, and some are decreasing. All of these behaviors are consistent with our simple theories of computer virus replication based upon an application of standard mathematical epidemiology to the problem [2]. They directly contradict predictions made by Tippett [3], who believes that all computer viruses will continue to replicate at an exponential rate until approximately 20% of the computer population is infected, after which they will continue to increase at a slower rate. Note that, even for those viruses which have increased in prevalence, it would be difficult to claim that the growth has been exponential, as claimed by Tippett. A linear fit to the growth curves would appear to do at least as well, if not better in most cases.
Figure 6: Number of incidents involving the most common viruses as a function of time. The units (incidents per 1000 PCs) pertain to our sample population only, but the curves should also be reasonable estimates of the relative worldwide prevalence of each virus. The data points are bracketed by bars indicating the statistical sampling error that one would expect given the number of observed incidents.
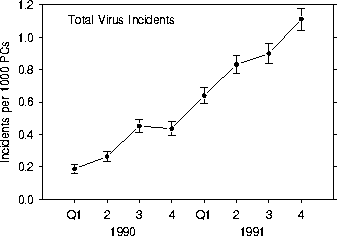
Figure 7 shows the relative frequency of incidents from all viruses as a function of time in our sample population. During the last quarter of 1991, about 0.1% of the PCs in our sample population became infected by some external source. This fraction is quite small, but it is rising. Part of this rise is due to the increase in the prevalence of individual viruses (e.g. the Stoned in Fig. 6). The other contributing factor is the increase in the number of different varieties of successfully-spreading viruses (e.g. the Joshi, which as shown in Fig. 6a first appeared in our sample population in late 1990). It should be recognized that the statistic shown here is distinct from that presented in Figs. 5 and 6, and can be thought of as a somewhat complicated combination of the two of them.
Figure 7: Total number of virus incidents in sample population as a function of time. The units (incidents per 1000 PCs) pertain to our sample population only, but the curve should also be proportional to the worldwide prevalence of all computer viruses as a function of time. The data points are bracketed by bars indicating the statistical sampling error that one would expect given the number of observed incidents.
The 1991 Dataquest survey [4] and the 1990 [3] and 1991 Certus surveys attempted to answer some questions relating to the prevalence of computer viruses. In addition, they addressed some issues relating to the costs and other consequences of incidents. As was mentioned in the introduction, these issues also have an important bearing on anti-virus policies, but lie beyond the scope of this paper. Where possible, we compare the results of the Dataquest survey to our own, reinterpreting their data where necessary. Details of the Certus surveys are not directly available to us, but fortunately a paper by Tippett [3] gives some overall results for the 1990 survey, and a few details of the 1991 Certus survey are reported in the Dataquest survey. Thus in a few cases we are able to compare our results to the Certus surveys as well.
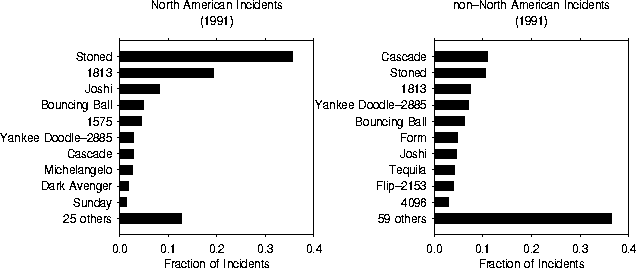
The Dataquest survey reported 48 different PC viruses in actual incidents during seven quarters of observation (from the first quarter of 1990 through the third quarter of 1991). In our somewhat smaller population, we observed 83 different viruses during 1991 alone. The Dataquest survey found the Stoned and 1813 (Jerusalem) viruses to be the two most common, as did we. However, they found that these two alone accounted for a surprising 89% of all incidents -- much more than our figures of 34% for 1991 and 51% for 1990. We are not able to account for this discrepancy completely, but a partial explanation for the significantly greater variety of viruses observed in our population is that it is international, whereas the Dataquest population was limited to North America. In order to provide a better basis for comparison to Dataquest's results, we have segregated our data on the relative frequency of viruses (presented earlier in Fig. 5) into North-American and non-North-American components in Fig. 8.
Figure 8: Relative frequency of virus incidents in 1991 in North America (left) and the rest of the world (right).
When we focus on North America only, the proportion of incidents due to Stoned and Jerusalem is increased from 34% to 55%, which is still considerably lower than Dataquest's 89%. The general character of the distribution is somewhat more in line with the Dataquest results -- a few viruses dominate, and only 35 different types are observed. The top ten viruses account for all but 13% of the incidents. We are in rather good agreement with Dataquest as to which viruses are the most prevalent. According to Fig. 5, the relative newcomer Joshi is next in line after Stoned and Jerusalem. Our lists of the ``Top Ten'' share eight viruses in common. Dataquest has seen more 4096 incidents than we have (it just missed our Top Ten), and we have seen considerably more instances of Michelangelo and 1575 (Green Caterpillar). The agreement is better than might be expected, given the problems inherent in the statistical sampling of rare events.
An unexpected benefit of segregating our data as we have done in Fig. 8 is that it brings to light a substantial difference in character between the relative prevalence of viruses in North America and that which exists in the rest of the world. A glance at Fig. 8 immediately demonstrates that the distribution of viruses is much more egalitarian outside of North America. Outside of North America, the Stoned and Jerusalem are still among the most common (demoted slightly to second and third place, respectively), but together they account for only 18% of the incidents. Nearly twice as many different viruses are observed (69 vs. 35), and the top ten viruses fail to account for over 37% of the incidents -- about three times the figure for North America. In addition, the specifics of which viruses are most common are somewhat different. The Cascade family (principally composed of 1701 and 1704), which is the seventh most common in North America, narrowly edges out Stoned for first place outside of North America. The Form, Tequila, and Flip-2153 viruses appear to be much more common outside North America. We do not as yet have a convincing explanation for the huge discrepancies between relative virus prevalence within and outside of North America. We pose this puzzle as a challenge to anyone (including ourselves) who wishes to develop a theoretical model of computer virus propagation.
Unfortunately, although we believe that quarterly statistics on the number of incidents involving some of the most common viruses were collected by Dataquest, an analysis of them is not yet available to us. Once it is, it will be very interesting to see how it compares with our Fig. 6.
A superficial look at the Dataquest results might lead one to conclude that they measured the total number of virus incidents as a function of time. Unfortunately, a closer look reveals that the statistic they report can not easily be interpreted in this way. What they actually report is the fraction of organizations that experienced one or more virus incidents during a given time period. This is not a very useful statistic as it stands, because it fails to distinguish between organizations with 100 PCs and organizations with 100,000 PCs. It would be very surprising and admirable if an organization with 100,000 PCs were to experience only one virus incident during a year! In the case of large organizations, one would like to know how many virus incidents there were, not just whether there were none or some.
Unfortunately, the statistic is not merely useless. It practically begs to be misinterpreted as a per capita figure by the press, since such a measure is much more useful and natural. Here is an excerpt from a recent New York Times article:
A recent survey of the computer virus problem by Dataquest, a San Jose, Calif., market research concern, showed that of 600,000 personal-computer users from North American businesses, 63 percent had experienced a computer virus and 38 percent of those reported a loss of data. [5]
The New York Times is not alone by any means. We are aware of other articles (e.g. one in the March 3, 1992 edition of World News Today) which make the same assumption. The unfortunate result of this is that the public is being told that the computer virus problem is about 1000 times worse than it really is.
We can try to salvage the Dataquest result by assuming that each of the 618,000 PCs in their sample population was equally likely to be infected by a virus of external origin. Fortunately, Dataquest includes in their analysis and summary a coarse-grained distribution of the size of the organizations they surveyed. In the appendix, we derive a formula which uses this distribution to convert the statistic that Dataquest reports into what we actually want: the average number of virus incidents per 1000 PCs during a specified time period. For example, Dataquest reports that, in 1990, the fraction of organizations experiencing one or more virus incidents was 26%. Using our formula, we find that this translates into a virus incident rate of 0.42 per 1000 PCs during 1990. This is approximately one third of the rate that we observed for 1990 (see Fig. 7). Dataquest's results of 19%, 25%, and 40% of organizations experiencing a virus during each of the first three quarters of 1991 translate into 0.27, 0.40, and 0.82 incidents per 1000 PCs, respectively. The third quarter result is remarkably close to our own observation of 0.90 incidents per 1000 PCs. Perhaps the similarity of our results for recent data indicates that this really is the current level of infection in the world's population. If this is the case, the factor of three discrepancy between the 1990 figures might be caused by fading memory on the part of the respondents, or a lesser awareness of the virus problem during 1990 than during 1991. However, the apparent agreement for the third quarter of 1991 could be mere coincidence, since the difference in the makeup of the two populations could cause the level of infection to be inherently different.
We can now use our derived virus incident rates to reconstruct approximately how many virus incidents one could expect in organizations containing a specified number of PCs. For example, in 1990, the derived incident rate of 0.42 per 1000 PCs means that a population of 100 PCs would have had about a 4.1% chance of having one or more incidents, a population of 1000 PCs would have had a 34.3% chance, and a population of 10,000 PCs would have had a 98.5% chance. An average over the distribution of organization sizes reported by Dataquest yields the 26% figure that they quote. This illustrates why their statistic is so very misleading -- it depends strongly on the organization size, as one would expect.
Pursuing our reconstruction a bit further, we can derive approximately the average number of incidents one would expect among organizations of a specified size that experienced at least one incident. Again, using the 1990 figure, we can expect the average number of incidents in a group of 100 PCs that experienced at least one virus to be 1.02, 1.22 for 1000 PCs, and 4.26 for 10,000 PCs. An average over the distribution of organization sizes reported by Dataquest yields 1.27 incidents per organization among those which experienced at least one. The figure of 4.26 for 10,000 PCs particularly illustrates the importance of asking how many incidents were experienced by a particular organization, rather than simply whether there were any. Apparently, Dataquest did attempt to ask how many incidents each organization experienced. However, in the very same figure in which they present the above results, Dataquest claims that the average number of incidents per organization that experienced one or more was 5 for 1990. What can explain the immense discrepancy between this and our derived figure of 1.27?
Let us abandon our mathematical transformation for just a moment and think about the problem intuitively. What could account for why 74% of all organizations were virus-free, while the other unfortunate 26% experienced an average of 5 incidents each during 1990? Divine wrath is a distinct possibility. However, we believe there is a rational explanation for this mystery. The problem can be traced to a set of ambiguously-worded questions in the survey, of which the following is an example:
- 3e.
- Were any viruses found on any PCs or diskettes during 1990?
If yes, record number.
A careful reading of the survey and conversations with Dataquest personnel and Dr. David Stang of the National Computer Security Association (which co-sponsored the survey) made it clear that the intent of this question was to determine how many virus incidents there were during the specified time period. However, the question can easily be interpreted to mean ``How many infected PCs or diskettes were there during 1990?'' If most of the interviewees interpreted the question this way, the reported statistic would reflect the number of infected PCs and diskettes, not the number of incidents. When alerted to this possibility, Stang quickly found further evidence supporting our conjecture: some respondents had given answers ranging from a few dozen to 100. He agreed that at least these particular answers probably represented the number of PCs and diskettes, not the number of incidents. We conclude that the wording of this set of questions in the survey blurred the vital distinction between the number of virus incidents and the number of infected PCs. It is clear from Dataquest's analysis and from conversations with Dataquest personnel that the designers of the survey were well aware of this distinction, but unfortunately it was not conveyed clearly to the respondents.
Forging ahead bravely, we can try to salvage the Dataquest results in the light of this reinterpretation. Suppose for the sake of argument that everyone misinterpreted the survey question, so that 5 actually represents the average number of infected PCs and diskettes for each organization that experienced a virus in 1990. Then, using our derived figure of 1.27 incidents for each such organization, we find that the average number of infected PCs and diskettes per incident was approximately 4. This is about 2.5 times the typical incident size in our sample population for 1991. Interestingly, it is reasonably close to the figure of 3.4 PCs that we observed in our population when anti-virus strategies were just being put in place. It may be that an average incident size of 3 to 4 PCs is typical of environments which are only weakly armed against viruses. This would offer further evidence that the anti-virus measures put in place in our sample population succeeded in reducing the virus problem substantially. It is possible that this seeming agreement is mere coincidence. Some respondents may have interpreted the survey question correctly, which would bias our estimate of the average incident size towards a value smaller than the actual one.
Now let us try to extract from the Dataquest data a notion of how the computer virus problem is changing with time. Dataquest succumbed to a number of pitfalls which we would like to point out so that future studies can avoid them. They recorded their statistic (which as we have discussed is not really meaningful without making further assumptions) during three or four time periods and fit the trend using Tippett's model of exponential growth. Unfortunately, Tippett's model applies to the increase in the number of copies of one particular virus, while the Dataquest statistic was (erroneously!) attempting to measure the growth in the number of incidents due to all viruses. As we noted in the previous section, the growth in the total number of incidents per quarter in Fig. 7 is due to both the increased prevalence of individual viruses and the increase in the number of viruses. The latter is purely a psychosociological phenomenon, and it is doubtful that any reliable theory explaining the number of new viruses as a function of time could be devised. Furthermore, even if the data were for one particular virus rather than all viruses combined, application of Tippett's model would be questionable for two reasons. First, there is good reason to doubt the model itself, both on theoretical grounds [2, 6] and on the basis of Fig. 6 of this paper (see previous section for a more detailed discussion). Second, even if Tippett's model were approximately correct, it would be extremely dangerous to fit an exponential to just three or four data points.
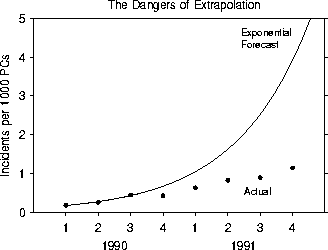
We illustrate this last point in Fig. 9. Suppose that, in Fig. 7, we only had data from the first three quarters of 1990. This is comparable to the amount of data upon which Dataquest and Certus based their estimates of the future course of the computer virus problem. The best exponential fit to these three points would give a ``doubling time'' of 4.7 months. In fact, this would fit comfortably between the values derived by Dataquest (5.2 months) and Certus (4.3 months). Then, we could use this doubling time to try to predict the number of incidents for each quarter through the end of 1991. How would we do? Terribly! The prediction gets worse and worse with time, and is off by nearly a factor of four after five quarters. The problem is not simply that the estimated doubling time is inaccurate. The data indicate that the entire concept of a doubling time is fundamentally flawed. This is demonstrated by the dramatic growth of the ``doubling time'' (which is supposed to be a constant quantity) with time. In an earlier Certus survey reported in [3], the doubling time for the virus problem as a whole between June, 1989 and June, 1990 was given as just 1.8 months. During the first three quarters of 1990, our data and that of Certus and Dataquest indicate a ``doubling time'' of 4 or 5 months. If we attempt to fit a doubling time to our 1991 data, we find that it is 12 months! We confidently predict that, if anyone still insists on measuring a doubling time for 1992, it will turn out to be noticeably longer than any that have been quoted so far.
Figure 9: Moral on the dangers of extrapolating from a small
number of data points. The data are the same as in Fig. 7.
An exponential curve with a ``doubling time'' of 4.7 months provided an
excellent fit to the number of observed incidents in our sample population
during the first three quarters of 1990. Extrapolation from this curve
predicts that the number of incidents should increase by a factor of 9.0
between the third quarter of 1990 and the fourth quarter of 1991. In fact,
the number of incidents increased by a factor of only 2.5 during that time
period, and the qualitative shape of the predicted curve is entirely wrong.
A linear fit would have been considerably better.
In summary, here is some advice for anyone who is planning to conduct a computer virus survey.
We hope that future surveys will take this advice, and make use of the suggestions for useful statistics that we have listed and discussed in this paper. With some debugging, future surveys could be a valuable complement to the study that we have conducted, giving us access to data from a larger and more diverse population.
The utility of studies like these is to understand the problem as it exists today and to point the way towards actions that can be taken to manage the risk. We have seen how difficult it can be to extract useful answers from such a study. Great care must be taken in framing the questions to be asked, and in interpreting the data that are collected.
We are interested in three broad sets of questions:
Once we understand (3), we should be able to predict the answers to (2). In the meantime, our current study focuses on measuring the answer to (2) over the last two years.
We have presented a methodology which involves careful collection of data on PC-DOS virus incidents from a stable, fixed population. We record the date and location of the incident, the name of the virus and the number of PCs that are infected. We record this data at the time of the incident, rather than depending upon the accuracy of people's memory. We can say very accurately which viruses we have seen in this population, when we first saw them, and how often we see them. In fact, only 15% to 20% of the more than 700 viruses in our collection have ever been seen ``in the wild'' in this population. Even among those that have been seen, a small minority of them account for the majority of incidents, with Stoned and 1813 accounting for about 34%, and the top ten viruses accounting for about 69%.
We analyzed incidents from the most frequently occurring viruses. Some, such as the Joshi virus, appear to be increasing in frequency. Others, like the Bouncing Ball and perhaps the 1813 virus, appear to have reached an equilibrium in which their frequency does not increase or decrease dramatically. Others, such as the Brain virus, are virtually extinct. This is in qualitative agreement with our theoretical model of computer virus spread [2].
The total number of virus incidents per quarter is increasing, though not as dramatically as others have predicted. Its increase is due to a combination of two effects: some viruses are becoming more prevalent, and the number of different viruses observed ``in the wild'' is increasing.
In the vast majority of incidents in our sample population, only a single PC is infected. Since we do not see large outbreaks of any particular virus, we are confident that there is very little spread within our sample population. On the other hand, we see that there are sustained, ongoing infections in the world outside of our sample population, at least for some viruses. Our reinterpretation of the Dataquest survey and results from our own studies suggest that populations of computer users within the business and government sectors that are only weakly armed against computer viruses can expect an average incident size of 3 to 4 PCs. Our most recent statistics indicate that the following simple steps can help control the problem, cutting this figure by more than half:
Since we know that PCs seldom get infected from within the sample population, we conclude that the number of incidents per quarter reflects the number of times an infected diskette has entered this population from the rest of the world. By measuring the increase in incidents in our sample population, we get an approximate measure of the relative increase in the number of infected PCs in the world as a whole.
We think that studies like those described here are an important way to start understanding the risks computer viruses pose in the world today. Surveys that carefully follow our advice can provide a valuable complement to our work. As we understand more about how computer viruses spread worldwide, we will be able to predict how these risks will change in the upcoming years. While we are making progress on this more global understanding, the models available today do not allow reliable predictions to be made. This will be an important part of our future work.
The authors are grateful to Ralph Langham and Dave Chess for their help in collecting and analyzing the data presented in this paper.
In this appendix we describe the transformation which allows us to extract an estimate of the the number of incidents per 1000 PCs from Dataquest's statistic and their reported distribution of organization sizes.
Within a specified time period (e.g. the year 1990), each PC has a small probability of being infected by some external source and thus serving as the initial seed for an incident within its organization. Let us assume that this probability is equal to p for each of the 618,000 PCs included in Dataquest's survey. We also assume that whether or not one particular PC serves as an initial seed for an incident has no effect on whether any other PC does so.
Consider an organization with n PCs. The probability that there
will be no incidents in the specified time period is simply ![]() for small p. Thus the probability for there to be one or more incidents
(the Dataquest statistic) in such an organization is approximately
for small p. Thus the probability for there to be one or more incidents
(the Dataquest statistic) in such an organization is approximately ![]() .
.
Now we must account for the distribution of organization sizes. Suppose that the fraction of organizations in the sample population of size n is given by f(n). Then a weighted average of the probabilities yields an overall Dataquest statistic of:
![]()
Only a coarse-grained version of f(n) was available to us. In other words, Dataquest reported the number of respondents with responsibility for between 100 and 250 PCs, 250 and 500 PCs, 500 and 1000 PCs, etc. For each of these bins, we divided the number of PCs by the number of respondents to obtain a representative size for each bin. For example, in the 100 to 250 PC category, 116 respondents accounted for 19,513 PCs. This gives a representative size of 168.2 PCs per organization in this category. Since there were 602 respondents in all, we set f(n=168.2) = 116/602 = 0.193. We followed the same procedure for each bin to obtain a reasonable approximation to the values of the other f(n).
All that remains is to invert Eq. 1 so that we can use the reported value of DQ (e.g. 0.26 for 1990) to determine p. An analytic solution is impossible, but a numerical solution is trivial. We just need to experiment with various values of p on the right-hand side until we obtain the correct value of DQ on the left-hand side. For our example of DQ=0.26, this yields p=0.00042.
We can expect the coarse-graining of the distribution to introduce a small amount of error, which will be easy to eliminate once the exact distribution becomes available.